We have an input vector \(X^T=(X_1,...,X_p)\) and want to predict a real-valued output \(Y\).The linear regression model has the form:
\[f(X) = B_0 + \sum_{j=1}^p {X_j\beta_j}\]
Typically we have a set of training data \((x_1, y_1)...(x_N, y_n)\) from which to estimate the parameters \(\beta\). The most popular estimation method is least squares, in which we pick \(\beta\) to minimize the residual sum of squares, (3.2): \[
\begin{align}
RSS(\beta)&=\sum_{i=1}^N(y_i-f(x_i))\\
&=\sum_{i=1}^N(y_i-\beta_0-\sum_{j=1}^p{x_{ij}\beta_j})^2
\end{align}
\]
How do we minimize (3.2)? We can write the (3.2) using matrix, (3.3): \[RSS(\beta)=(\mathbf{y}-\mathbf{X}\beta)^T(\mathbf{y}-\mathbf{X}\beta)\]
Differentiating with respect to \(\beta\) we obtain: \[
\begin{align}
\frac{\partial{RSS}}{\partial\beta} = -2\mathbf{X}^T(\mathbf{y}-\mathbf{X}\beta)
\end{align}
\]
Assuming that X has full column rank, and hence the second derivative is positive definite: \[\mathbf{X}^T(\mathbf{y}-\mathbf{X}\beta)=0\]
and the unique solution is: \[\hat{\beta}=(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y}\]
The predicted value at an input vector \(x_0\) are given by \(\hat{f}(x_0)=(1:x_0)^T\hat{\beta}\):
The matrix \(\mathbf{H}=\mathbf{X}(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\) is sometimes called the “hat” matrix.
Geometrical representation of the least squares: We denote the column vectors of X by \(x_0, x_1, ..., x_p\). These vectors span a subspace of \(\mathcal{R}^N\), also referred as the column space of X. We minimize \(RSS(\beta)=||\mathbf{y}-\mathbf{X}\beta||^2\) by choosing \(\hat{\beta}\) so that the residual vector \(\mathbf{y} - \hat{\mathbf{y}}\) is orthogonal to this subspace and the orthogonality is expressed by \(\mathbf{X}^T(\mathbf{y}-\mathbf{X}\beta)=0\). The hat matrix H is the projection matrix.
Sampling properties of \(\hat{\beta}\): In order to pin down the sampling properties of \(\hat{\beta}\), we assume that the observations \(y_i\) are uncorrelated and have constant variance \(\sigma^2\), and that the \(x_i\) are fixed. The variance-covariance matrix is given by (3.8):
Under (3.9), it is easy to show that (3.10): \[
\hat{\beta} \sim N(\beta, (\mathbf{X}^T\mathbf{X})^{-1}\sigma^2)
\]
Also (3.11): \[(N-p-1)\hat{\sigma}^2 \sim \sigma^2\chi_{N-p-1}^2\]
a chi-squared distribution with N-p-1 degrees of freedom and \(\hat{\beta}\) and \(\hat{\sigma}\) are statistically independent.
Hypothesis test: To test \(H_0: \beta_j = 0\) we form the standardized coefficient or Z-score: \[
z_j=\frac{\hat{B}_j}{\hat{\sigma}\sqrt{v_j}}
\]
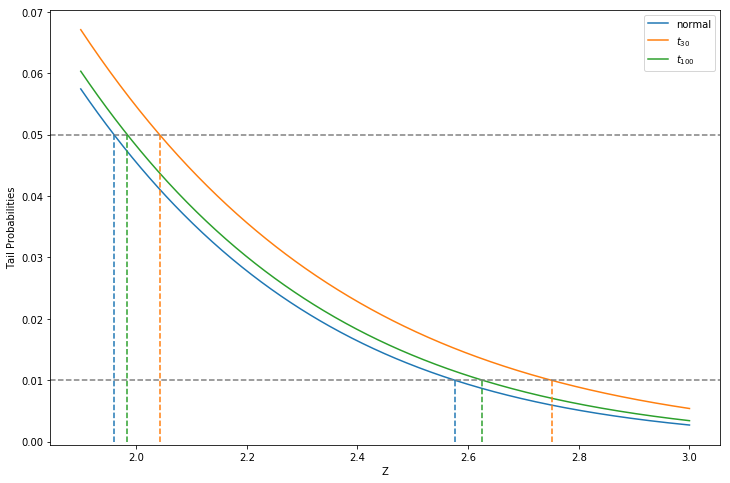
where \(v_j\) is the jth diagonal element of \((\mathbf{X}^T\mathbf{X})^{-1}\). Under the null hypothesis \(z_j\) is distributed as \(t_{N-p-1}\), and hence a large value of \(z_j\) will lead to rejection. If \(\hat{\sigma}\) is replaced by \(\sigma\) then \(z_j\) is a standard normal distribution. The difference between tail quantiles of a t-distribution and a standard normal become negligible as the sample size increases, see the Figure (3.3) below:
Where \(RSS_1\) is for the bigger model with \(p_1+1\) parameters and \(RSS_0\) for the nested smaller model with \(p_0+1\) parameters. Under the null hypothesis that the smaller model is correct, the F statistic will have a \(F_{p_1-p_0,N-p_1-1}\) distribution. The \(z_j\) in (3.13) is equivalent to the F statistic for dropping the single coefficient \(\beta_j\) from the model.
Similarly, we can isolate \(\beta_j\) in (3.10) to obtain \(1-2\alpha\) confidence interval (3.14) \[(\hat{\beta_j} - z^{(1-\alpha)}v_j^{\frac{1}{2}}\hat{\sigma}, \hat{\beta_j} + z^{(1-\alpha)}v_j^{\frac{1}{2}}\hat{\sigma})\]
In a similar fashion we can obtain an approximate confidence set for the entire parameter vector \(\beta\) (3.15): \[ C_{\beta} = \{{\beta|(\hat{\beta}-\beta)^T\mathbf{X}^T\mathbf{X}(\hat{\beta}-\beta)} \le \hat{\sigma}^2{\chi_{p+1}^2}^{(1-\alpha)} \}\]
where \({\chi_{l}^2}^{(1-\alpha)}\) is the \(1-\alpha\) percentile of the chi-squared distribution of \(l\) degrees of freedom.